前言
此次爬的是bilibli创作中心的播放量相关数据,地址如下
https://member.bilibili.com/platform/upload-manager/article
网址分析
首先用chrome打开网站,然后按F12打开调试窗口,点击network标签页,然后再次刷新网页
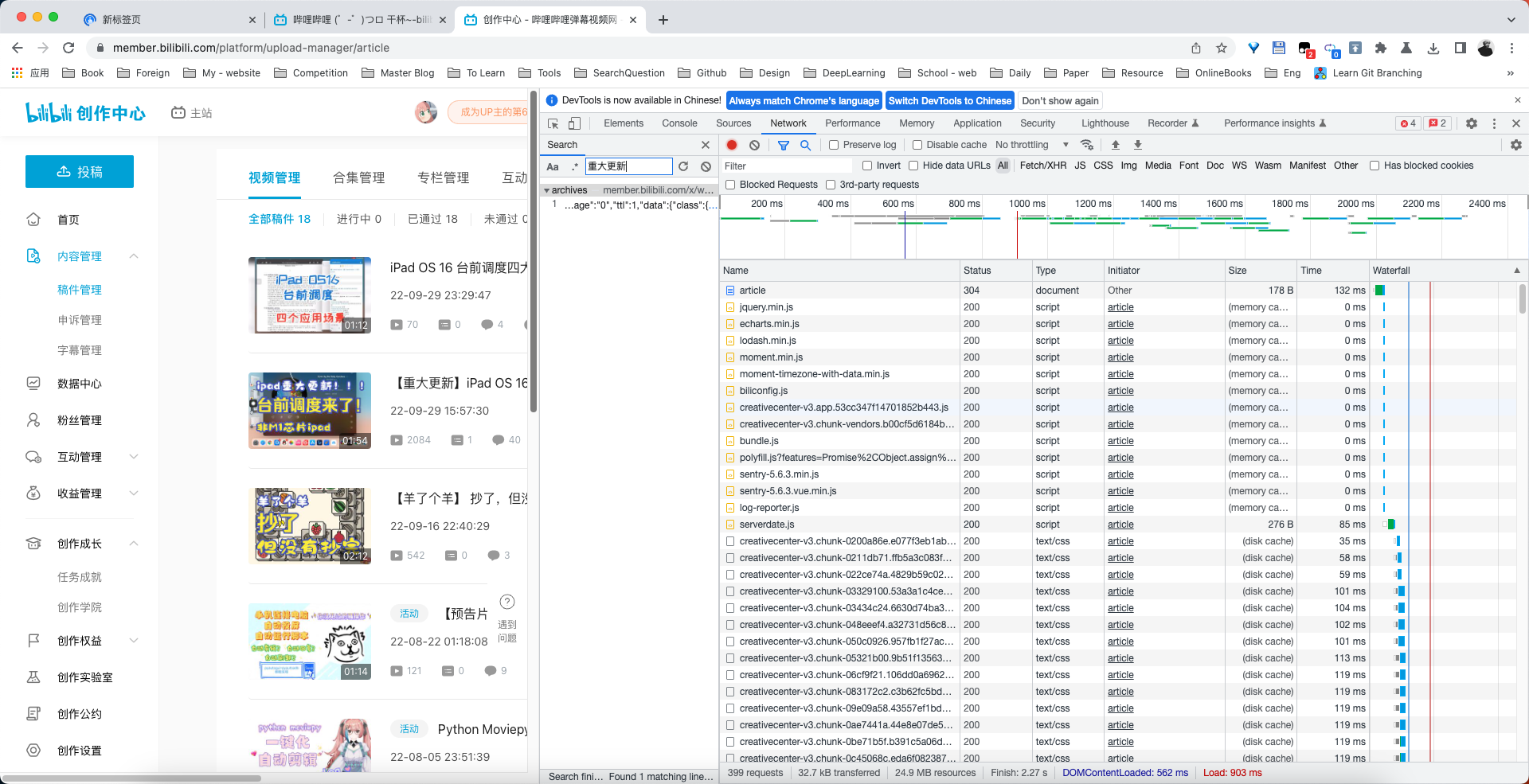
1.首先分析出该网站的请求头
根据左侧现实的内容,按ctrl+f对网页请求到的数据进行检索关键字,推荐检索数字、英文,一般数字英文不会进行编码,汉字可能进行二次编码了。
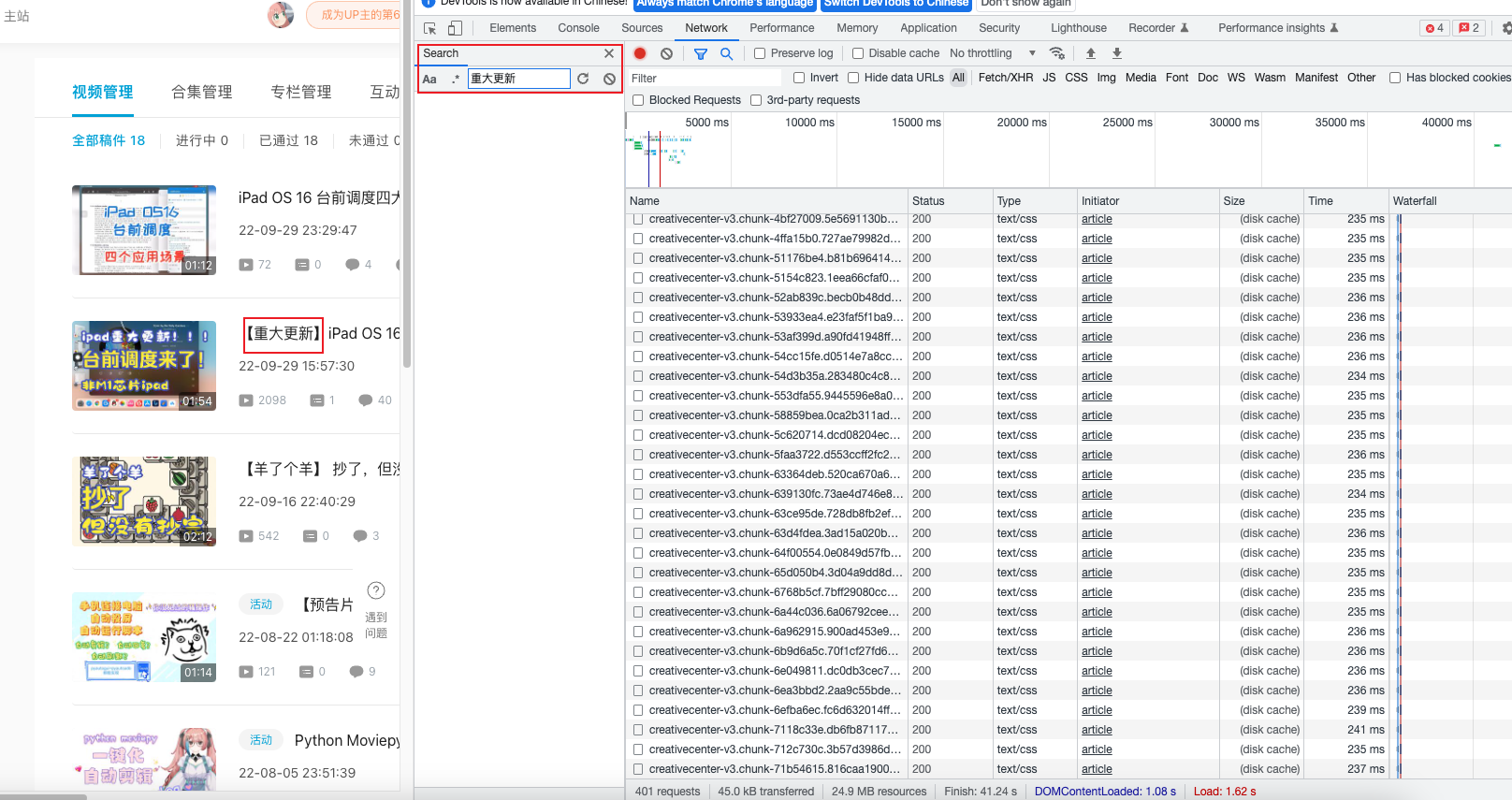
点击搜索可以看到对应的搜索结果,点开搜索结果,点击headers标签页,然后可以看到下方有request headers这个就是浏览器向服务器请求网页时用到的请求头。
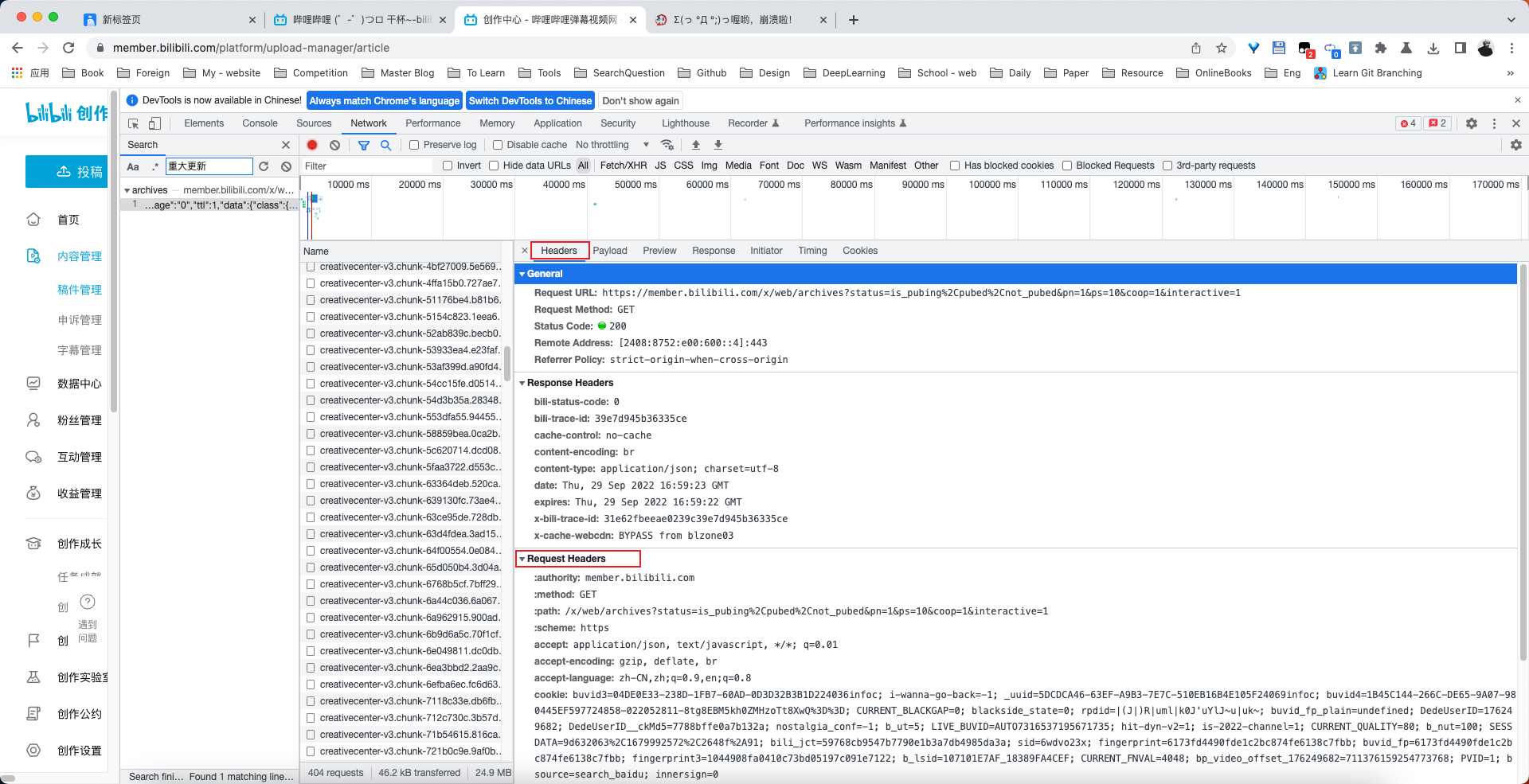
这里直接复制即可,然后粘贴到vscode,通过我编写的chromeHeaderFormat()函数可以对浏览器复制的请求头自动格式化为标准请求头。
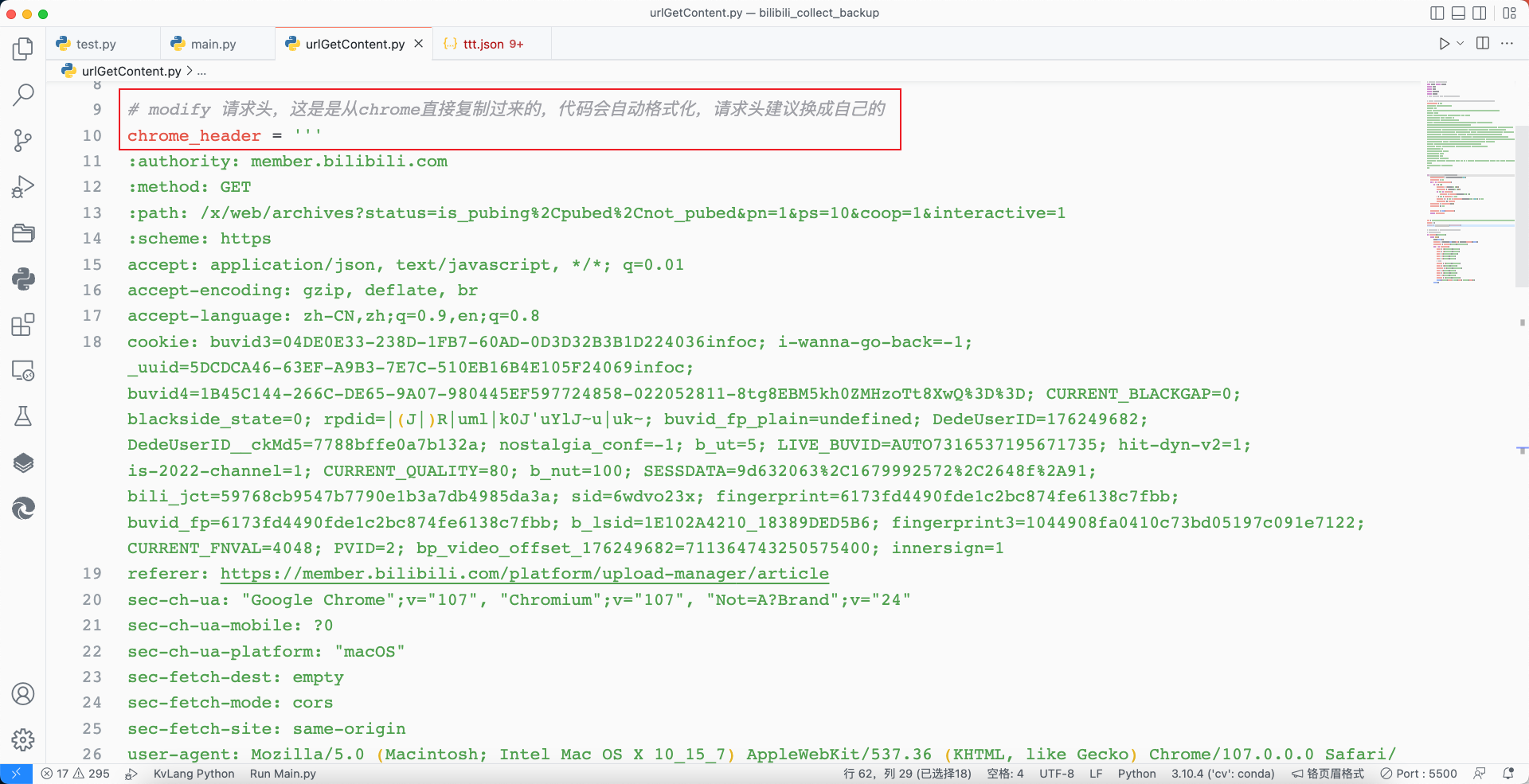
chromeHeader格式化函数
def chromeHeaderFormat(chrome_header):
header_param_list = chrome_header.split('\n')
header_dict = '{'
for i in header_param_list:
if i != '':
param_key = i.split(': ')[0]
param_value = i.split(': ')[1]
if ':' in param_key:
param_key = param_key.replace(':', '')
t = '"' + param_key + '":'
one_line = t + '"' + param_value.replace('"', '\\"') + '",'
header_dict += one_line
header_dict = header_dict[:-1]
header_dict += '}'
header_dict = eval(header_dict)
return header_dict2.分析请求的主机地址
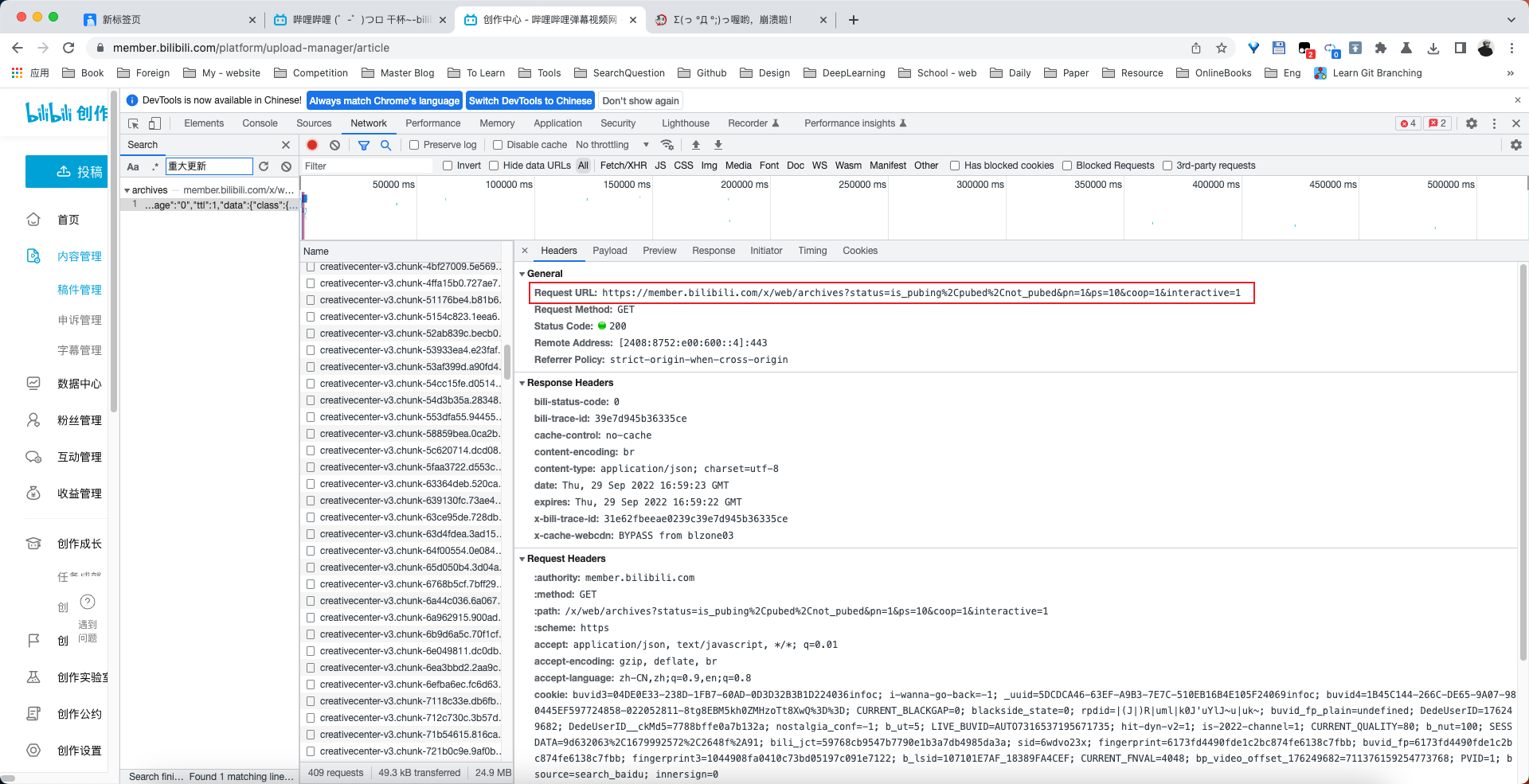
3.分析响应头
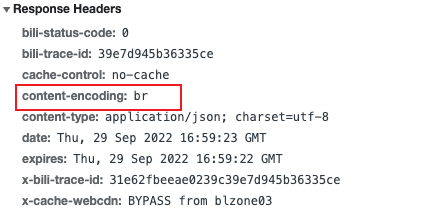
这里的内容编码格式使用了br编码,python爬虫获取到的数据可能是乱码,这里需要导入
import brotli
response = requests.get(url=url, headers=headers).json()获取网页数据并解析
通过request.get().json()获取主机发来的json数据解析即可。


